1.简介
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。
ShardingSphere已经在2020年4月16日从Apache孵化器毕业,成为Apache顶级项目。 欢迎通过shardingsphere的dev邮件列表与我们讨论。

定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
2.数据分片
分片相关概念:
1 | 逻辑表- 业务逻辑表。 例如:订单表o_order 订单明细表o_order_item 因为量大 都需要分库 |
垂直拆分
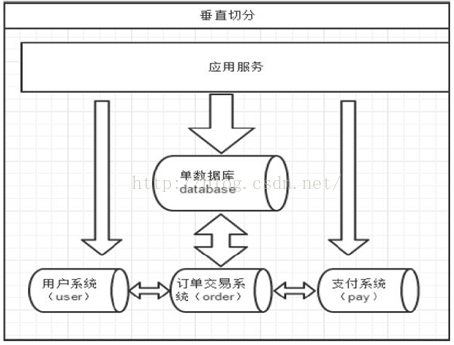
优点:
1. 拆分后业务清晰,拆分规则明确。
统之间整合或扩展容易。
3. 数据维护简单。缺点:
1. 部分业务表无法join,只能通过接口方式解决,提高了系统复杂度。
2. 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
3. 事务处理复杂。
水平拆分
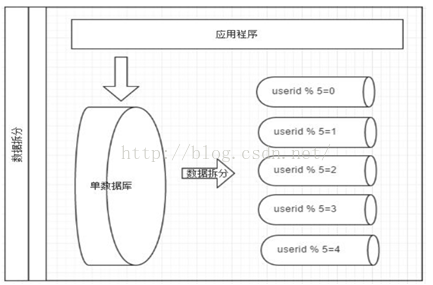
优点:
1. 不存在单库大数据,高并发的性能瓶颈。
应用透明,应用端改造较少。
3. 按照合理拆分规则拆分,join操作基本避免跨库。
高了系统的稳定性跟负载能力。缺点:
1. 拆分规则难以抽象。
片事务一致性难以解决。
3. 数据多次扩展难度跟维护量极大。
库join性能较差。2.SpringBoot+MybatisPlus+Sharding-JDBC集成 单库分表
版本依赖,注意如果用有的数据库池的版本会跟Sharding-JDBC版本冲突,以下是我搜了半天,能够运行成功的版本依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29<properties>
<shardingsphere.version>4.0.0-RC2</shardingsphere.version>
</properties>
<!--sharding spring boot -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${shardingsphere.version}</version>
</dependency>
<!--sharding spring namespace -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>${shardingsphere.version}</version>
</dependency>
<!--druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>
<!-- mybatis-plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1</version>
</dependency>若还用其他bug和问题,直接找github源头,那里会有人提交bug,和一些解决方案。
数据库:字段设计都必须一致

文件配置,我这里只做了一个单库分表,跟着官网上来配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37#spring配置
spring:
#数据源配置
shardingsphere:
datasource:
names: m1 #配置库的名字,随意
m1: #配置目前m1库的数据源信息
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/xiaozhu?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=GMT%2B8&useSSL=false
username: root
password: root
sharding:
tables:
user_account:
key-generator:
column: uid
type: SNOWFLAKE
# 分库策略,以uid为分片键,分片策略为uid % 2 + 1,user_id为偶数操作m1数据源,否则操作m2。
actual-data-nodes: m1.user_account_$->{0..99}
table‐strategy: #分表策略
inline:
sharding‐column: uid
algorithm‐expression: user_account_$->{uid % 2 + 1}
props:
sql:
show: true #打印sql
mybatis-plus:
# datasource: dataSource
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
mapper-locations: classpath:/mapper/*.xml
type-aliases-package: com.stephen.xiaozhuanalysis.project.entity
server:
port: 8083运行sql,无需对controller,service,mapper等原代码进行改动。
1
2
3
4
5
void test1(){
List<UserAccount> userAccounts = userAccountMapper.selectList(null);
userAccounts.forEach(System.out::println);
}结果:
